Research Data Management
왜 연구데이터관리가 중요한가
연구데이터관리는 그 중요성이 날로 커가고 있습니다. 연구자 개인의 필요 뿐 만 아니라 연구 진실성 검증을 위해서, 또한 연구비 지출의 효율성을 제고하고자 하는 연구비지원기관의 정책을 만족시키기 위해서도 꼭 필요합니다.
특히 새로운 연구 경향의 하나인 데이터 중심 연구는 무수한 연구 장비로부터 쏟아져 나오는 데이터 자원을 보존 및 분석하여 데이터에 잠재되어 있는 새로운 가치를 발견해 내는 연구 방식입니다. 데이터를 통한 연구자들의 협업을 이끌어 내기 위해서도 데이터의 재사용성을 보장하는 체계적인 데이터 관리가 필요합니다. 주요 선진국에서는 이러한 데이터가 국가의 자산이라는 인식하에 데이터의 체계적인 보존과 접근성을 확보하기 위해 다양한 활동을 전개하고 있습니다.
- ▶ 연구데이터 관리를 통해 얻을 수 있는 효과는 다음과 같습니다.
-
- 언제든 필요할 때 찾아볼 수 있습니다.
- 불필요한 중복 작업을 피할 수 있습니다.
- 필요한 경우 연구 결과를 검증할 수 있습니다.
- 연구에 대한 가시성을 확보하고 영향력을 높일 수 있습니다.
- 타 연구자의 인용을 가능하게 합니다.
- 연구비지원기관의 요구사항을 만족시킵니다.
주요 국가에서는 연구비지원기관의 정책 및 연구기관(대학) 차원의 정책을 통하여 연구데이터의 체계적인 관리와 공유를 견인해 나가고 있습니다. 또한 대다수의 학술 저널 출판사의 경우도 저널 논문과 함께 연구데이터와 관련한 정보를 받고 있습니다. 그러나 이들 출판사는 일반적으로 연구데이터에 접근 가능한 식별자 정보를 받고 있으며, 원시데이터의 유지 및 관리 책임은 논문의 저자나 연구기관에 있다고 판단하고 있습니다.
국내의 경우 연구데이터관리의 중요성에도 불구하고, 각 연구소나 대학을 중심으로 생산된 연구데이터는 주로 학술연구를 통한 논문 형태로 결과물이 제시되고 있을 뿐 원시데이터는 대부분 사라지고 있는 실정입니다. 특히, 측정·분석·실험을 통해 생성되는 연구데이터는 천문학적인 비용과 노력이 수반되는 소중한 자원으로서 이의 보존, 공유 및 재활용을 통해 국가 자원을 효율적으로 활용할 필요가 있으나 연구 후 소멸되거나 개별 연구자 또는 연구실 단위로 관리되고 있는 현실입니다.
BSL 은 조만간 대두될 연구데이터관리 이슈에 능동적으로 대처하기 위하여, 연구데이터에 대한 체계적인 관리와 공유를 지원하고, 연구자가 필요한 연구데이터를 손쉽게 찾아서 활용할 수 있는 서비스를 개발하는 노력을 해 나갈 것입니다.
연구데이터란 무엇인가
연구데이터를 정의하는 것은 쉽지 않습니다. 아직 정의에 대한 합의가 되어 있지 않으며, 분야에 따라 서로 다르게 사용되고 있기 때문입니다. 여러 정의가 있을 수 있으나, 연구데이터(Research data)란 '연구 결과를 만들어내기 위한 분석을 목적으로 수집, 관찰 또는 생산된 데이터' 정도로 이야기 할 수 있겠습니다. 연구데이터가 발생되는 소스는 다양하겠으나, 다음과 같이 네 가지 정도의 카테고리로 나누어 볼 수 있습니다.
- ▶ Observational (관측 및 관찰데이터)
-
- Captured in real-time (실시간 생성)
- Usually irreplaceable (일반적으로 재생산 불가)
- Examples: Sensor readings, telemetry, survey results, images
- ▶ Experimental (실험데이터)
-
- Data from lab equipment (연구실 장비에서 생산)
- Often reproducible, but can be expensive (재생산 가능한 경우가 많으나, 고비용일 수 있음)
- Examples: gene sequences, chromatograms, magnetic field readings
- ▶ Simulation (시뮬레이션데이터)
-
- Data generated from test models (실험 모델로부터 생산)
- Models and metadata, where the input more important than output data (모델과 메타데이터, 입력 데이터가 결과보다 중요)
- Examples: climate models, economic models
- ▶ Derived or compiled (추출 및 컴파일데이터)
-
- Reproducible (but very expensive) (재생산 가능하나 매우 고가임)
- Examples: text and data mining, compiled database, 3D models
각 데이터의 특성에 따라 데이터 관리 계획 또한 달라지게 됩니다.
Research Data Management에 대하여
데이터 중심 연구 환경과 국가 자산으로서의 데이터 관리 요구는 연구자에게 연구데이터의 체계적인 관리를 요구하게 됩니다. 연구자에게 있어 체계적인 데이터 관리 요구는 ‘데이터 관리 계획서(DMP - Data Management Plan)’ 작성으로 이어집니다.
DMP는 주로 연구비지원기관이 연구비를 지원받는 연구자에게 요청합니다. 일반적으로 연구과제 신청시 DMP를 함께 제출할 것을 요구합니다. DMP에 담겨야 할 주요 내용은 과제 수행을 통해 생산되는 데이터의 종류와 형태는 무엇인지? 데이터를 어디에 보존할 것이며 데이터로의 영속적 접근을 어떻게 보장할지? 등으로 구성됩니다.
개별 연구자의 DMP 작성을 지원하기 위해, 연구기관(대학)에서는 ‘연구데이터 관리 서비스(Research Data Management Service, RDMS)’를 제공하는 것이 일반적입니다. 이러한 역할은 도서관과 같은 조직에서 주로 수행합니다.
DMP 의 실행에 있어서는 그 무엇보다 연구자의 적극적인 참여가 중요합니다. 관리대상 연구데이터에 대해 누구보다도 데이터의 상황정보(누가, 언제, 어떻게 데이터를 생산하였는지?)를 잘 알고 있기 때문입니다. 이러한 상황정보가 원시데이터와 함께 잘 관리될 때 데이터의 재사용성을 보장할 수 있게 됩니다.
국내에서는 한국지질자원연구원이 연구과제 제안시 DMP 작성을 의무화하고 있습니다.
연구데이터 출판(Publishing)과 데이터 식별자
데이터의 재사용성을 높이기 위해 데이터 식별자를 부여하여 데이터의 물리적 위치 변동과 상관없이 데이터에 영속적인 접근이 가능하도록 해야 합니다. 이를 위해 연구데이터에 식별자를 부여하여 유통시키기 위한 DataCite 컨소시엄이 활동하고 있습니다.
일반적으로 데이터 식별자로는 DOI(Digital Object Identifier) 가 사용되고 있습니다. 연구자가 자신의 데이터에 식별자를 부여하기 위해서 별도의 작업이 필요하지는 않습니다. DOI 부여 기능이 있는 연구데이터 관리시스템에 데이터를 등록하는 과정에서 시스템적으로 자동할당되는 형태가 대부분입니다.
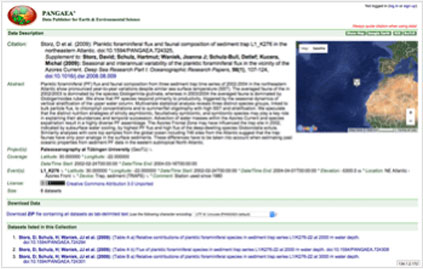
아래는 DOI를 통한 데이터 출판과 기존 저널 서비스와의 연계 사례를 보여줍니다. PANGAEA(Data Publisher for Earth & Environmental Science) 에 등록(출판)된 데이터와, Elsevier 출판사의 ScienceDirect 에 출판된 저널 논문은 각각 DOI 를 통해 식별됩니다. 이들은 연계를 통해 연구 논문의 추가 정보로서 연구데이터를, 연구데이터의 참고 정보로서 연구 논문을 연결하여 서비스하고 있습니다.
-
- ▶ ScienceDirect - Journal Article Publisher Site

-
- ▶ PANGAEA - Data Publisher Site